Trong thời đại kỹ thuật số phát triển nhanh chóng như ngày nay, một lượng lớn tin tức trực tuyến khiến việc cập nhật thông tin ngày càng trở nên khó khăn. Tại MediaX, chúng tôi tự hào công bố nghiên cứu mới này giúp thay đổi cách tiếp nhận tin tức Tiếng Việt. Được dẫn dắt bởi Nguyễn Đình Tuấn, nhóm nghiên cứu của chúng tôi đã phát triển một phương pháp mới để tóm tắt tin tức, khai thác sức mạnh của mô hình BERT để tạo ra các bản tóm tắt ngắn gọn, giàu thông tin cho các bài báo tiếng Việt.
Những thách thức trong bài toán tóm tắt tin tức Tiếng Việt
Tiếng Việt, với cú pháp phức tạp và hình thái phong phú, đặt ra những thách thức đặc biệt cho việc tóm tắt văn bản tự động. Các phương pháp tóm tắt truyền thống thường gặp khó khăn trong việc tạo ra những bản tóm tắt mạch lạc, nắm bắt được ý nghĩa sắc thái của bài viết gốc. Điều này đã thôi thúc chúng tôi tìm kiếm một giải pháp mới nhằm hiểu được các đặc trưng của tiếng Việt mà vẫn giữ được bản chất của nội dung gốc.
Giới thiệu Mô hình BLLA: Giải pháp mới cho bài toán tóm tắt văn bản
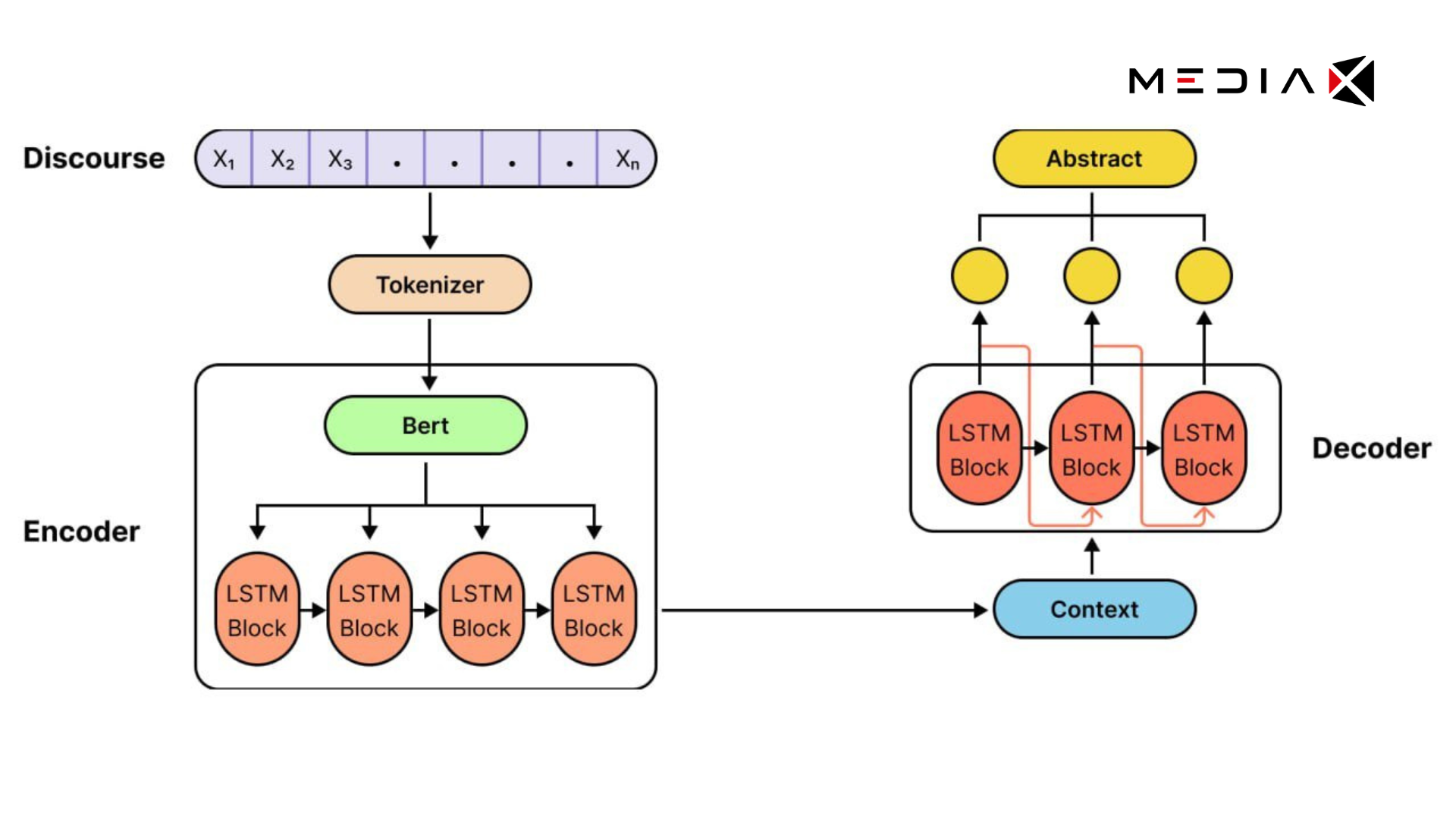
Nghiên cứu của chúng tôi là phát triển sử dụng mô hình BERT-LSTM-LSTM với sự hỗ trợ của lớp Chú ý (BLLA). Mô hình đổi mới này kết hợp sự hiểu biết sâu sắc về ngữ cảnh của BERT với khả năng xử lý tuần tự của mạng LSTM, được nâng cao hơn nữa nhờ cơ chế Chú ý. Sự kết hợp này cho phép tóm tắt hiệu quả các bài báo tiếng Việt, tạo ra những bản tóm tắt vừa chính xác vừa mạch lạc.
- Hiểu biết sâu sắc về ngữ cảnh nhờ BERT: Mô hình BLLA tận dụng BERT để hiểu ngữ cảnh của văn bản tiếng Việt, cho phép mô hình nắm bắt được những ý nghĩa tinh tế trong các bài báo.
- Xử lý tuần tự với LSTM: Dựa trên những hiểu biết sâu sắc của BERT, các lớp LSTM xử lý các khía cạnh tóm tắt theo trình tự, đảm bảo các bản tóm tắt được tạo phản ánh mục đích của bài viết gốc.
- Tăng cường chất lượng của bản tóm tắt với cơ chế Chú ý: Lớp chú ý cho phép mô hình tập trung vào các phần có liên quan nhất của các bài báo, đảm bảo các bản tóm tắt vừa ngắn gọn vừa toàn diện.
Tạo bộ dữ liệu mới phục vụ cho bài toán Tóm Tắt
Chìa khóa cho nghiên cứu của chúng tôi là việc tạo ra hai bộ dữ liệu riêng biệt được thiết kế riêng để huấn luyện mô hình BLLA ở các mức độ phức tạp khác nhau:
- Bộ dữ liệu được đơn giản hóa: Bao gồm các cặp tiêu đề và ba câu từ các bài báo, bộ dữ liệu này tập trung vào việc tóm tắt thông điệp cốt lõi một cách rõ ràng.
- Tập dữ liệu tóm tắt đúng nghĩa: Bao gồm các bản tóm tắt được tạo từ mười câu của bài viết, ban đầu được tạo bởi API GPT và được xử lý lại bởi con người, tập dữ liệu nhằm mục đích huấn luyện mô hình BLLA trên một đầu vào và đầu ra chi tiết hơn.
Những bộ dữ liệu này là công cụ để đào tạo mô hình giúp mô hình học những vấn đề phức tạp của việc tóm tắt tin tức bằng tiếng Việt, bắt đầu từ những nhiệm vụ cơ bản đến những thách thức phức tạp hơn, giống người hơn.
Kết quả đạt được, hiệu suất này không chỉ nhấn mạnh tiềm năng của mô hình mà còn tạo ra một phương pháp mới cho bài toán tóm tắt văn bản dựa trên AI.
Hướng nghiên cứu trong tương lai
Nghiên cứu này đánh dấu một bước tiến đáng kể trong hiểu biết và ứng dụng AI của MediaX trong xử lý ngôn ngữ. Tại MediaX, chúng tôi cam kết tiếp tục khám phá các công nghệ AI để tạo ra các giải pháp giúp mọi người dễ tiếp cận và hấp dẫn hơn với thông tin.
Hãy theo dõi để biết thêm thông tin cập nhật khi chúng tôi tinh chỉnh các mô hình của mình và khám phá các giới hạn mới trong xử lý ngôn ngữ tự nhiên và hơn thế nữa.